Memory leaks and wild stats
posted by Jeff | Thursday, February 8, 2024, 10:58 PM | comments: 0When I turned the forums into a product a few years ago (that I've never marketed, so I have as many customers as you'd expect), I built in a lot of redundancy and performance features, so you could host many forums under different names, but under the covers it would be just one app. In other words, the PointBuzz forums and the testing forums are the same app, they just look different. On top of that, there are two copies running, and the traffic is split between the two. It runs in just 200MB and can still easily handle a thousand requests per minute (that works out to 8 per second on each instance, so there's obviously room to grow). And that's on one virtual CPU and 1.75 gigs of RAM. I could scale it up (more power) or out (more instances), for a very long runway. Even with the two nodes, it rarely replaces one or "goes bad."
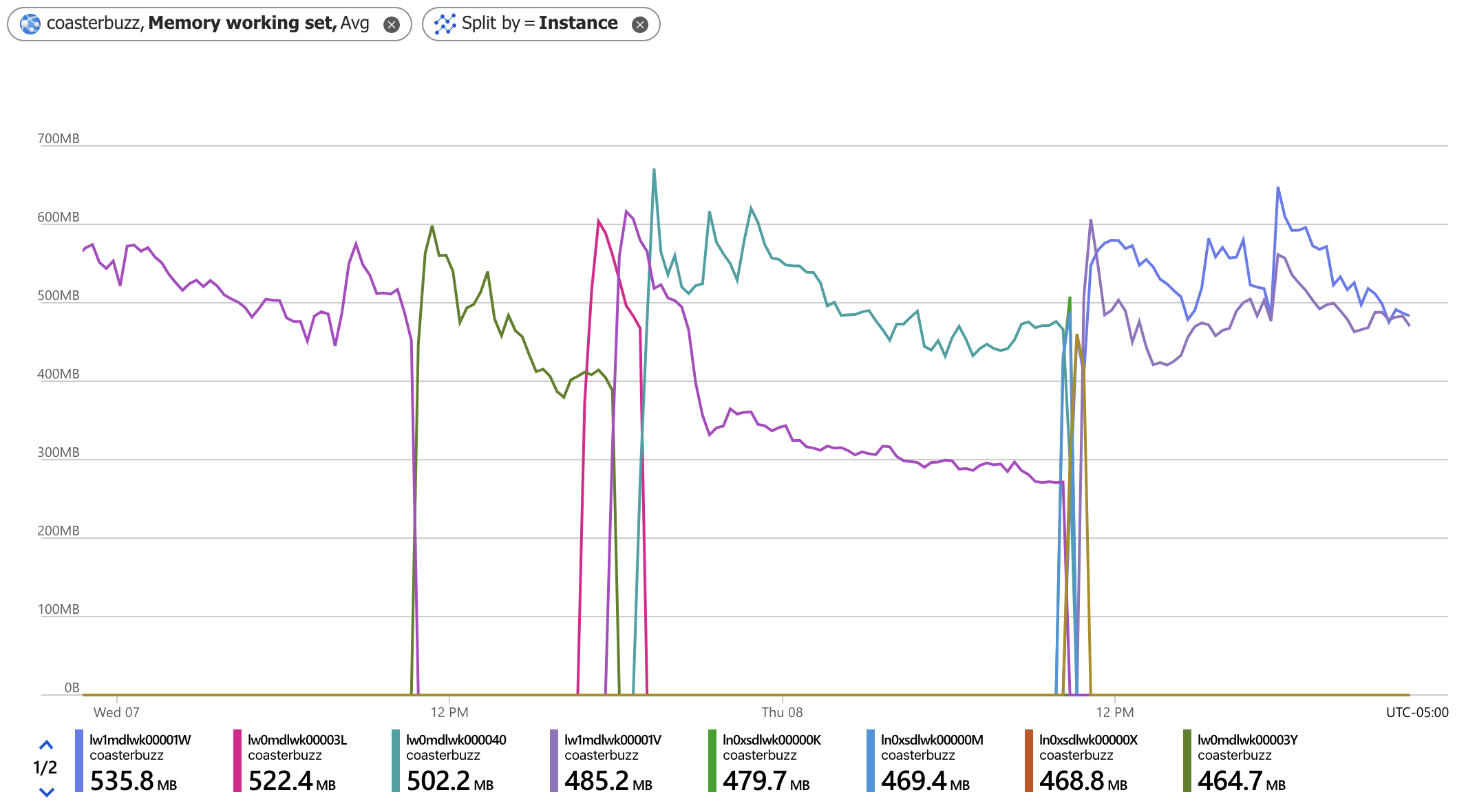
CoasterBuzz and the not-forum part of PointBuzz (and this blog and other stuff) run on a separate virtual machine, and it has 2 virtual CPU's and 3.5 gigs, but it was just one node. The whole point of having more than one is if it crashes or something else bad happens, the other one keeps up until a new one can be provisioned automatically. It has been crashy for a long time, and uses a lot more memory. Usually this means it stops responding for a minute or two, but comes right back. I started to notice it more, so I wanted to bump it to two or more nodes. Doing this requires some plumbing I didn't have in place, so I added it, and went to two nodes. And that's when it got weird.
The first thing that I noticed is that both instances would get traffic for a bit, then it would only go to one. No point in paying for two if only one is working. If I scaled it up or down, it would go back to two for awhile, then drop down back to one. My first hint came when the portal said that both instances were unhealthy, which I didn't understand, because I could hit both (you can hack your ARR cookie to go to either one).
My first suspicion was that CoasterBuzz had a memory leak. Sure, it does more things outside of the forum, like serve photos and do news and stuff, but it's not substantially more. I started auditing the code, and I did find some database connections that weren't in a C# using block, but I did close them and they should have been disposed at the end of the request. But whatever, I fixed them up. Overnight, same thing, it dropped down to one.
I was poking around the instrumentation and found that there were hundreds of requests that were redirects, and it was a flat line. That meant something mechanical was doing it. Then, as I was looking around at the site code, I realized that I had a mechanism that redirected any request that wasn't to coasterbuzz.com. Not www.coasterbuzz.com, and definitely not the underlying included name that included azurewebsites.net. Then it hit me... the health check mechanism was hitting the root of the site, and it was doing it at the azurewebsites.net, which I was 301 redirecting. The health check mechanism considers anything not a 2xx return code as unhealthy.
I made a new health check URL on the site, and excluded it from the redirecting, just for Azure's health check mechanism. Suddenly, both of my instances appeared healthy, and traffic was consistently being served to both. Not only that, but the flood of 301's stopped appearing in the logs. That made me happy, though I didn't really understand what was going on.
It wasn't until I RTFM'd that I really understood what was going on. If one of your instances is deemed unhealthy, it diverts traffic to the healthy ones, and spins up a replacement. But it'll only replace one instance per hour, and three per day, or maybe some other limit based on the scale level. The doc says both. But either way, it means you get down to one instance no matter what, and it keeps running it even though it thinks that it's "unhealthy." In reality it wasn't, it just thought it was because of my redirects. That's why I would end up with just one, but also two would stay up if I scaled it in or out (which I did because I would go to three instances when I deployed new versions of the app, as it never appears down that way).
Clouds are hard. But everything is easier when you read the documentation.
Comments
No comments yet.